Hệ thống gợi ý nhạc hay phim thường cần trả lời: “bài / tác phẩm nào gần với thứ người dùng đang xem?” Khi mỗi bài nhạc hoặc mỗi phim được biểu diễn bằng một vector số (embedding), khoảng cách giữa hai vector cho biết mức độ tương đồng theo một định nghĩa cụ thể. Trong PostgreSQL, cosine distance là một lựa chọn rất phổ biến cho bài toán này — đặc biệt khi dùng extension pgvector.
Embedding là gì?
Embedding là cách máy tính mô hình hóa lại nội dung (lyrics, mô tả phim, genre, mood, poster text, v.v.) thành một dãy số cố định gọi là chiều — ví dụ 10 hoặc 15 chiều tương ứng với dãy 10 hoặc 15 số — sao cho các nội dung tương đồng về ngữ nghĩa thường có vector gần nhau trong không gian đó. Vector gần nhau là như thế nào ta tìm hiểu bên dưới.
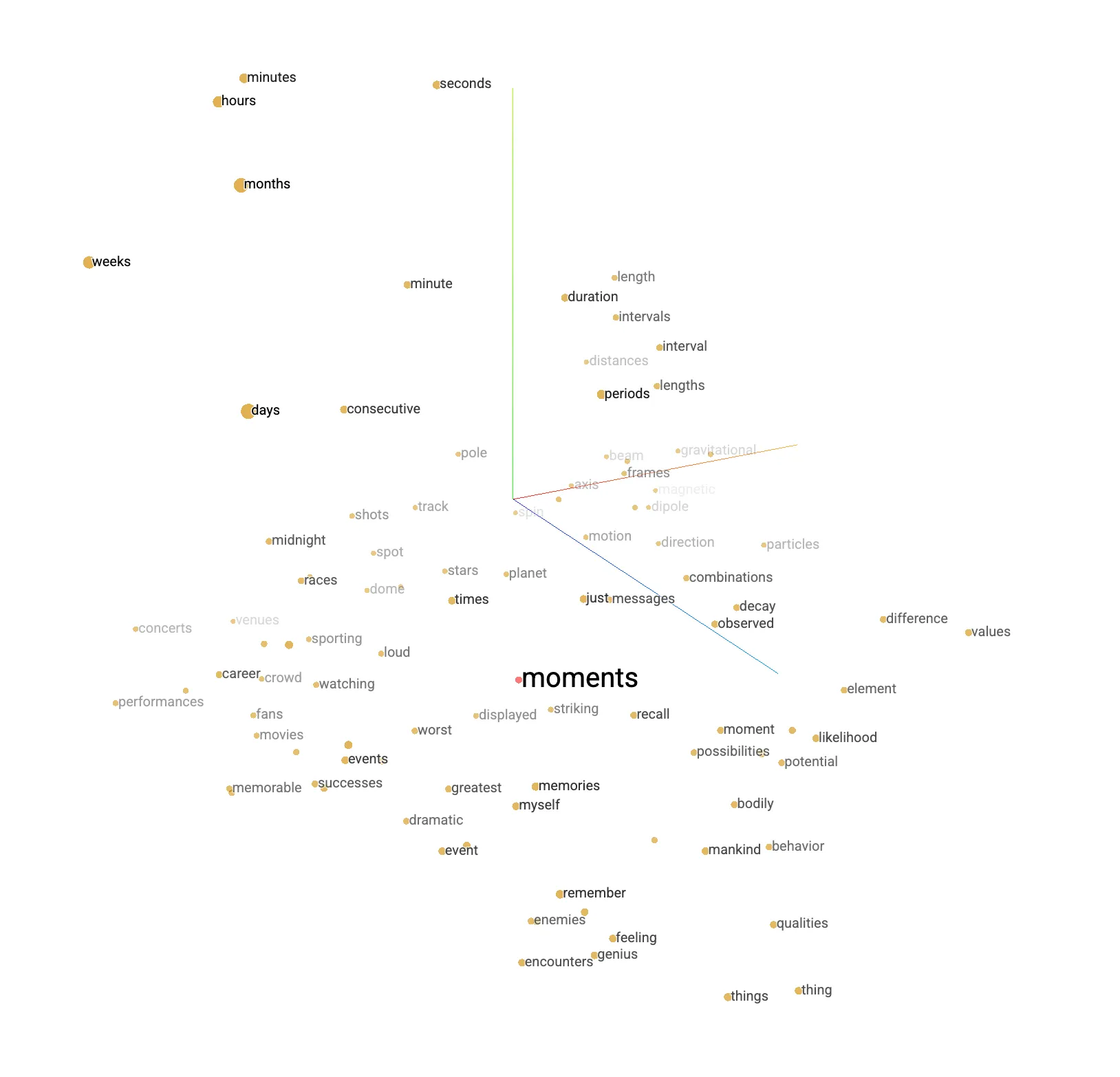
Để nhìn embedding nhiều chiều trên mặt phẳng hoặc trong 3D, mở Embedding Projector: trang có sẵn vài dataset mẫu đã được embed — đây là mô phỏng lên không gian 3D cho ta cái nhìn trực quan, các điểm gần nhau là có sự tương đồng nhất định so với các điểm xa nhau.
Để có được embedding, bạn không cần tự huấn luyện mô hình: nhiều nhà cung cấp cho API trả về vector sẵn, chẳng hạn Google AI Embeddings (Gemini / các mô hình embedding của Google Cloud).
Cosine similarity và cosine distance
Với hai vector a, b cùng số chiều:
Phiên bản dễ hiểu
- Cosine similarity: đo hai vector cùng hướng đến mức nào — càng cao (gần 1) thì hai embedding càng giống nhau về nghĩa mà mô hình đã học, chứ không phải “điểm này cách điểm kia bao nhiêu mét” theo nghĩa địa lý.
- Cosine distance: đổi similarity thành một khoảng cách — càng nhỏ (gần 0) thì càng giống; trong truy vấn gợi ý, ta thường lấy các vector có distance nhỏ nhất làm láng giềng.
Cosine similarity — giải thích chi tiết
- Tính bằng tích vô hướng (dot product) của a và b chia cho tích độ dài Euclidean của từng vector — tức cosin của góc giữa hai vector trong không gian.
- Giá trị thường nằm trong khoảng −1 đến 1; với embedding văn bản nhiều khi chủ yếu là nửa dương (gần 0 đến 1).
Cosine distance — giải thích chi tiết
- Dạng hay dùng trong thư viện và DB: lấy 1 trừ đi cosine similarity — hai vector càng “cùng hướng” thì khoảng cách càng nhỏ.
- Cùng một danh sách vector, xếp hạng theo similarity giảm dần hay theo distance tăng dần cho ra cùng thứ tự “ai giống ai nhất”.
Hai đại lượng này thứ tự xếp hạng giống nhau: vector nào có similarity cao thì distance thấp. Vì vậy “top-K gợi ý” có thể viết theo ORDER BY cosine distance ASC hoặc ORDER BY cosine similarity DESC — tùy API bạn đang dùng.
Điểm mạnh của cosine so với khoảng cách Euclidean thuần (L2) trong gợi ý nội dung: nó chuẩn hóa theo độ dài vector — hai bài nhạc cùng “hướng” ngữ nghĩa nhưng embedding có norm lớn nhỏ khác nhau vẫn có thể so sánh công bằng hơn khi bạn quan tâm góc giữa hai vector hơn là độ lớn tuyệt đối.
Trong PostgreSQL với pgvector
Extension pgvector thêm kiểu vector(n) và các toán tử khoảng cách. Với cosine, toán tử thường gặp là <=> (cosine distance theo định nghĩa của pgvector — tương ứng “càng nhỏ càng giống”).
Ví dụ lược đồ tối giản cho bài hát:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE TABLE tracks (
id bigserial PRIMARY KEY,
title text NOT NULL,
embedding vector(768) -- chiều khớp với model embedding bạn chọn
);
CREATE INDEX ON tracks USING ivfflat (embedding vector_cosine_ops)
WITH (lists = 100);Gợi ý “bài giống bài đang nghe” (vector query là embedding của bài hiện tại):
SELECT id, title, embedding <=> :query_vec AS dist
FROM tracks
WHERE id <> :current_id
ORDER BY embedding <=> :query_vec
LIMIT 20;Ứng dụng gợi ý nhạc / phim (ở mức sản phẩm)
- “More like this”: một embedding cho mỗi entity; nearest neighbors theo cosine distance.
- Session / playlist: có thể trung bình (mean pool) embedding của vài bài vừa nghe rồi tìm láng giềng quanh vector trung bình đó — vẫn sort bằng
<=>với vector truy vấn đã gộp. - Lọc cứng (hard filter): thêm
WHERE language = 'vi'hoặcWHERE rating >= 4trước khi sort; khi index ANN không hỗ trợ filter phức tạp, pattern phổ biến là lấy candidate rộng rồi lọc trong ứng dụng hoặc dùng các kỹ thuật hybrid (metadata index + vector).
Cosine distance trong PostgreSQL không “hiểu” nhạc hay phim — nó chỉ đo gần xa trong không gian embedding mà bạn đã chọn. Chất lượng gợi ý phụ thuộc phần lớn vào nội dung nào được đưa vào model, cách cập nhật vector khi catalog đổi, và chỉ số đa dạng (tránh bubble chỉ một cluster).
Tóm lại
- Embedding: vector đặc trưng nội dung; có thể lấy qua API (ví dụ Google) rồi lưu trong PG.
- Cosine distance trong pgvector (
<=>vớivector_cosine_ops): đo độ “cùng hướng” giữa hai vector, rất hợp cho top-K láng giềng trong gợi ý nhạc và phim. - Triển khai: bảng có cột
vector(n), index phù hợp, truy vấnORDER BY embedding <=> query— phần còn lại là thiết kế text đầu vào embedding và trải nghiệm người dùng.